DATA. It takes centre stage for all science projects – its definition, collection, organisation, analysis and as a significant part of the resulting outcome.
Yet, it has traditionally been the scientific paper that takes precedence as the vector for knowledge, with its core data relegated to a few tables locked into print format. The bulk of the collected data is left in lab books, spreadsheets and analysis software formats in the scientist’s office, or at best as supplementary digital data tables on the journal’s website.
What happens at the two ends of a scientific project can be the most critical. Once a ‘research question’ has been proposed, defining what data must be collected and the methods that ensure rigour and accuracy of recording data become paramount. Poor project design can kill a project. Likewise, once ‘the paper’ is out, where does the data go?
Data capture is increasingly being aided by automation, such as sensors that measure one parameter accurately, repeatedly and automatically submitting the data points to the scientist digitally. Smartphone apps are now commonly used to improve the accuracy of observations by providing their users with accurate automated data on geo-location and date/time, as well as controlled vocabularies for each form field.
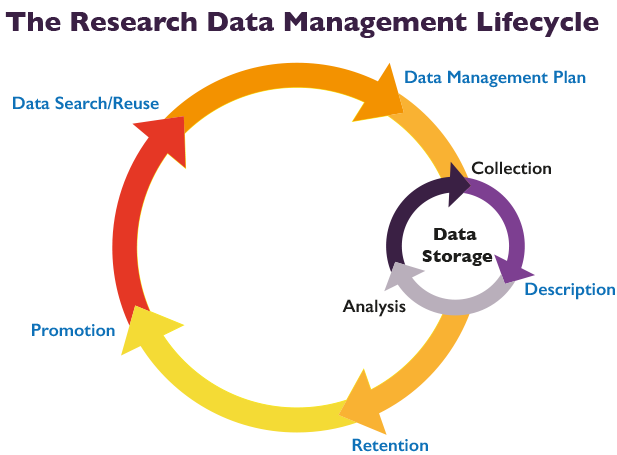
Submitted data is then stored in a project data repository where administrators can vet, validate, curate and download data for further analysis. While the project is active the data is maintained; but, once the paper is out and the research funds dry up? In the figure above, the ideal ‘life cycle’ is illustrated.
Nature Science Data provides a best practice model for projects that result in a scientific publication. It mandates the release of datasets with accompanying Data Descriptors, instructs authors to submit datasets to an appropriate public data repository, and maintains a list of vetted data repositories.
To make the data maximally retrievable and reusable, (globally) agreed data standards are crucial. One example from the biological realm is the Biodiversity Information Standards (TDWG), a non-profit scientific community dedicated to developing biodiversity data standards.

In my neck of the science woods, herbarium and museum collections provide an excellent long-term store of absolutely raw data, in the form of a preserved specimen from which multiple researchers over time can extract useful data. With the digitisation revolution in recent decades this fundamental biodiversity has been captured and liberated through institutional websites (eg. FloraBase – the Western Australian Flora) and federated to provide national (Atlas of Living Australia) and global (Global Biodiversity Information Facility) data portals.
For example, as part of UWA’s honey bee project I scored phenological data for a eucalypt species complex using Access to Biological Collection Data (ABCD) standard fields. This data was appended to metadata in the WA Herbarium’s specimen database to become available to researchers around the world.
So, a clearly conceived Data Management Plan should be essential for any scientific research and Citizen Science projects are no different. However, CS projects commonly have a very low funding base, run for just a relatively short period and may be related to a single researcher’s project for which the outcome is a thesis or paper. If a project ends and the digital datasets are not adequately archived in a useable format in a major searchable repository then that hard-won data cannot be maximally discoverable and re-usable.
A good fall-back in this situation would be to at least lodge the data and metadata in the Australian National Data Service (ANDS). ANDS aims to make Australia’s research data assets more valuable for researchers, research institutions and the nation. The site contains many guides to standards, methods and contribution – and is well-worth referring to when considering your next research project.
If you’d like to know more about how we can help you with developing a citizen science program, please leave a comment below, connect with us on Twitter, LinkedIn or Facebook, or email me directly via alex.chapman@archive.gaiaresources.com.au.
Alex
Comments are closed.